

| Shots | 0 | 1 | 2 | 4 | 0 | 1 | 2 | 4 | 0 | 1 | 2 | 4 | 0 | 1 | 2 | 4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Datasets | ScienceQAIMG | OKVQA | TextVQA | TextVQAocr | ||||||||||||
| MMC4 | - | 1.6 | 3.9 | 11.6 | 8.6 | 23.6 | 21.5 | 28.7 | 12.1 | 16.2 | 16.8 | 20.9 | 14.5 | 23.9 | 29.9 | 34.7 |
| MMC4-Core-ff | - | 2.1 | 10.1 | 10.2 | 11.8 | 21.2 | 25.3 | 30.4 | 13.6 | 18.7 | 18.8 | 22.1 | 16.1 | 26.6 | 28.7 | 33.1 |
| OBELICS | - | 2.8 | 3.0 | 16.4 | 13.0 | 31.7 | 35.7 | 37.5 | 9.2 | 26.5 | 30.2 | 32.2 | 11.0 | 30.7 | 36.3 | 41.0 |
| Textbook-6.5M | 26.3 | 29.4 | 25.1 | 37.3 | 10.2 | 31.2 | 36.8 | 39.9 | 11.8 | 26.7 | 32.1 | 33.5 | 14.1 | 33.1 | 36.4 | 42.8 |
| Dataset | MathVista | MathVision | MathVerse | Avg. | ||||||||||||
| MMC4 | 20.4 | 30.0 | 27.9 | 26.0 | 12.2 | 21.3 | 15.5 | 16.1 | 8.6 | 19.4 | 21.2 | 15.9 | 10.9 | 19.4 | 19.5 | 21.9 |
| MMC4-Core-ff | 22.5 | 33.0 | 29.2 | 27.8 | 13.7 | 23.4 | 16.3 | 17.7 | 8.6 | 19.9 | 21.8 | 15.2 | 12.3 | 20.7 | 21.4 | 22.3 |
| OBELICS | 21.6 | 28.5 | 31.1 | 27.6 | 13.4 | 20.1 | 16.8 | 14.9 | 6.9 | 19.4 | 20.7 | 14.0 | 10.7 | 22.8 | 24.8 | 26.2 |
| Textbook-6.5M | 24.3 | 43.4 | 33.2 | 29.2 | 14.5 | 25.6 | 18.2 | 18.1 | 7.7 | 28.5 | 19.8 | 14.6 | 15.5 | 31.1 | 28.8 | 30.8 |
We continued pre-training the base model of LLaVA-1.5-7B using different interleaved datasets. The results are evaluated on 4 common VQA and 3 math-related benchmarks under few-shot settings.
| Dataset | Continual Pre-training from Idefics2-8B-base | Pre-training Idefics2-8B from scratch | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| OKVQA | TextVQA | MathVista | MathVision | MathVerse | OKVQA | TextVQA | MathVista | MathVision | MathVerse | |
| MMC4-cf | 54.1 | 57.7 | 27.8 | 14.0 | 17.3 | 9.4 | 25.1 | 24.0 | 13.3 | 18.3 |
| OBELICS | 54.6 | 57.5 | 27.6 | 14.3 | 17.5 | 10.5 | 25.7 | 24.2 | 13.6 | 17.7 |
| Textbook-6.5M | 55.1 | 58.2 | 29.7 | 16.2 | 19.4 | 10.1 | 26.8 | 26.1 | 14.4 | 19.8 |
Except for LLaVA, we also pre-train advanced VLMs with multi-image ability (Idefics): continual pretraining from Idefics-8B-base or pre-training from scratch. The evaluations are extended to an 8-shot using randomly selected examples as previous works.
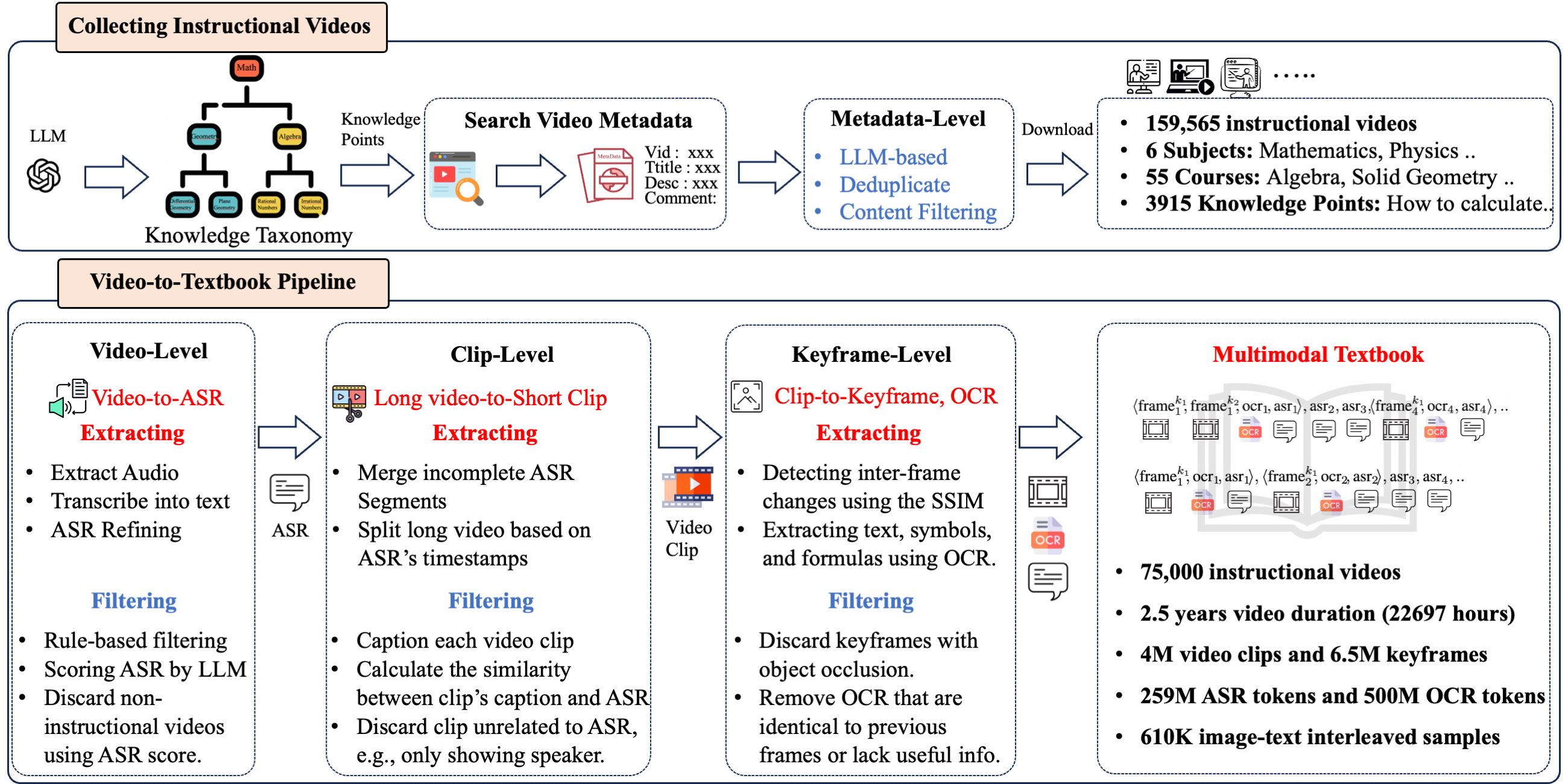
We synthesize knowledge taxonomy with 3915 knowledge points across 6 subjects, which enabled us to automatically collect 159k English instructional videos based on this taxonomy. Following our video-to-textbook pipeline, we filter 53% low-quality or repetitive videos and retain 75k videos (22,697 class hours) with an average duration of 18 minutes. Then we extract 6.5M keyframes and 0.75B text (ASR+OCR) tokens from these videos. We produce a total of 610K interleaved samples. Each sample contains an average of 10.7 keyframes and 1,297 text tokens. The detailed statistics for each subject is as follows:
| Textbook Subject | #Video | Duration (h) | #Topic | #Video Clip | #Keyframe | #ASR Token | #OCR Token | #Sample |
|---|---|---|---|---|---|---|---|---|
| Mathematics | 21.7k | 4,423 | 725 | 809k | 1.67M | 72.5M | 145M | 123k |
| Physics | 11k | 3,511 | 530 | 822k | 0.95M | 36.7M | 73.4M | 119k |
| Chemistry | 4.5k | 2,643 | 410 | 234k | 0.49M | 15M | 30M | 32k |
| Earth Science | 12k | 3,670 | 520 | 640k | 1.03M | 40M | 80M | 88k |
| Engineering | 13k | 4,096 | 810 | 713k | 1.15M | 43.3M | 86.6M | 98k |
| Computer Science | 12.8k | 4,354 | 820 | 782k | 1.21M | 42.8M | 85.5M | 150k |
| All | 75k | 22,697 | 3,915 | 4M | 6.58M | 258M | 500M | 610k |
The statistics of our multimodal textbook.
The Earth science textbook explores fields such as geology, meteorology, and oceanography through combinations of theoretical diagrams and actual images.


In chemistry domain, our textbooks cover a wide range of knowledge from basic chemical reactions to complex molecular structures. Through detailed experimental demonstrations and theoretical explanations, our textbook can help VLMs deeply understand chemical principles.


Computer science textbook cover core contents such as programming fundamentals, data structures, and algorithm analysis. Through animations and code examples, abstract concepts become more concrete and easy to understand for VLMs.


The mathematics textbook systematically introduces important concepts from elementary mathematics to advanced mathematics. Through step-by-step, image-text interleaved derivation processes and intuitive geometric figures, it helps VLMs master mathematical thinking.


The physics textbook mainly focuses on mechanics and thermodynamics knowledge. Through vivid demonstrations and tutorial texts, it enables VLMs to understand physical laws and natural phenomena.


The physics textbook mainly focuses on mechanics and thermodynamics knowledge. Through vivid demonstrations and tutorial texts, it enables VLMs to understand physical laws and natural phenomena.
